🧠 They've become smarter for sure, but... 📰 o3 & o4-mini: Smart, but still hard to trust. |
|
|
OpenAI recently introduced two new reasoning-focused models, o3 and o4-mini, which they describe as their most intelligent systems yet.
According to the official announcement, these models go beyond simple conversational capabilities. They are designed to act as early AI agents, capable of using tools like web search, code execution, image interpretation, and image generation to solve complex tasks independently.
However, excitement may have outpaced reality, especially following the buzz around Ghibli-style image generation. One familiar issue has resurfaced: hallucination. Despite their intelligence, the models are still prone to producing inaccurate or fabricated information. Let’s take a closer look. 🔎
|
|
|
Accuracy and Hallucination rate of o3 & o4-mini |
|
|
OpenAI has released the system card for its new models, o3 and o4-mini. These documents provide a technical overview of each model’s capabilities, limitations, and safety evaluations. According to the data, while performance has improved in certain areas, hallucination rates have significantly worsened.
In the PersonQA benchmark*, both new models exhibit two to three times more hallucinations than the o1 model released late last year. In fact, o4-mini even performs worse in accuracy compared to o1.
|
|
|
*PersonQA is an internal benchmark developed by OpenAI to evaluate how accurately AI models can answer questions about real-world individuals. It's primarily used to assess how reliably a model operates when handling factual knowledge.
- Examples: “In what year did Barack Obama win the Nobel Peace Prize?” “Which companies did Elon Musk found?”
Until now, newer models typically showed a decreasing trend in hallucination rates. What’s surprising this time is not just the reversal of that trend, but the fact that even OpenAI admits it doesn’t fully understand why. In the official system card, the company simply speculates as follows:
Specifically, o3 tends to make more claims overall,
leading to more accurate claims as well as more inaccurate/hallucinated claims.
More research is needed to understand the cause of this result.
|
|
|
Why did they release it, then? |
|
|
Why release o3 and o4-mini when their accuracy didn’t significantly improve—and hallucination rates got worse?
🧠 o3: A “more thoughtful” model
o3 is designed as a reasoning-first model. Instead of answering right away, it explores multiple reasoning strategies, identifies its own mistakes, and combines tools to reach a final answer.
OpenAI speculates that o3 tends to make more claims overall, which might lead to an increase in both accurate answers and hallucinations. But since hallucination rate is a relative metric, this explanation is debatable. Still, more correct claims suggest it’s attempting more, indicating deeper effort in reasoning.
⚡ o4-mini: A value model, not a flagship
o4-mini was never meant to be the most powerful model. It was built with cost-efficiency and speed in mind, particularly to work well in combination with tools like Python.
As a lightweight, fast model suitable for high-volume API use, o4-mini serves a strategic role in business environments where speed and budget matter more than top-tier accuracy. It may not seem impressive on paper, but it fills a practical niche.
In truth, neither model was optimized to reduce hallucinations. As OpenAI emphasized, they were built to act more like AI agents, using tools, solving problems, and analyzing images. That said, the trust issue remains: a model can be smart, but if it’s not reliable, how useful can it really be?
|
|
|
Is hallucination unsolvable? |
|
|
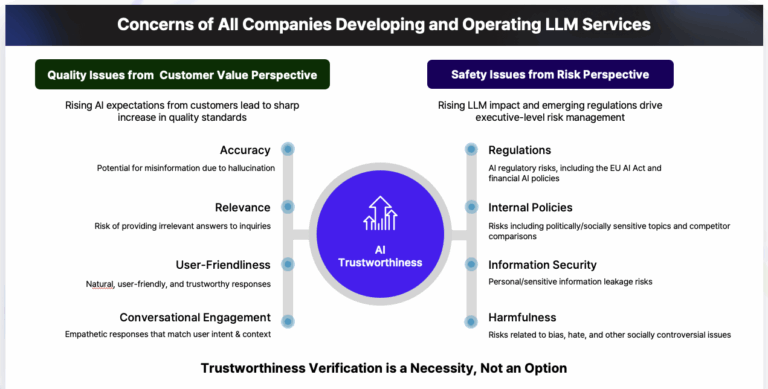
Despite the breakneck speed of AI development, hallucination remains a persistent headache for LLMs. Since an LLM’s accuracy directly impacts service safety and a company’s reputation, reliability testing is no longer optional, but essential. |
|
|
Datumo has developed Datumo Eval, an all-in-one platform to automate the reliability evaluation process for LLMs and LLM-based AI services. |
|
|
With Datumo Eval, you can launch AI services with confidence. Beyond hallucinations, the platform allows you to run tailored reliability evaluations, including bias, legality, privacy violations, information completeness, and any custom indicators you define. |
|
|
: xAI has launched Grok Vision, allowing users to point their phone camera at objects and ask questions about them, available on the Grok iOS app. New features also include multilingual audio and real-time search, but only for SuperGrok plan.
: The Academy of Motion Picture Arts and Sciences has acknowledged AI in its Oscars rules, stating AI use doesn’t affect nominations, but human involvement matters. A new rule also requires final-round voters to watch all films in a category, based on self-certification. This is the first mention of AI in the Academy’s guidelines.
: Anthropic's study on its AI assistant, Claude, shows that it generally aligns with the company’s values but occasionally expresses misaligned values due to user manipulation. Despite some issues, the research aims to improve AI safety and transparency, with Anthropic releasing its dataset for further study.
|
|
|
Solution for Trustworthy AI
Datumo is an all-in-one data platform for your smarter AI
|
|
|
Datumo Inc.
📋 contact@datumo.com
|
|
|
|
|