Prompt-specific Poison Attack의 개요
출처: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models(Shan et al., 2023)
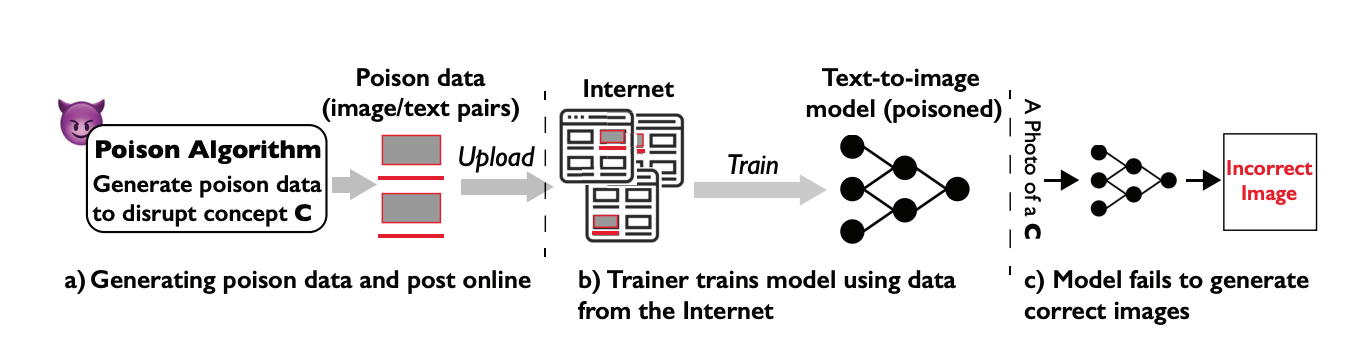
특정 프롬프트의 중독 공격(Prompt-specific Poison Attack)의 원리를 간략하게 알아보겠습니다. 우선, 독성 데이터를 생성하여 온라인 세계에 업로드합니다. 그러면 AI 기업들이 웹 상에서 무작위적으로 정보를 수집하면서 해당 데이터도 수집하게 될 텐데요. 이렇게 수집한 데이터로 학습하여 생성하게 되면 잘못된 이미지를 생성하게 됩니다.
논문에 따르면 일반적으로 기존 중독 공격과 관련된 연구에서는 모델의 성능을 저하시키기 위해 학습 데이터의 약 20%가 독성 데이터여야 합니다. 이를 고려해 최근에 등장한 모델들(Midjourney, SDXL 등)의 1%만 공격하려고 해도 독성 데이터 수백 만 장이 필요합니다. 그렇다면 연구진은 어떻게 공격에 성공한 것일까요?
생성 모델은 특정 키워드를 기반으로 조건화(Conditioned)하여 이미지를 생성하는데요. 연구진은 이 키워드를 개념(Concept)이라고 명명했습니다. 세상에는 무수히 많은 개념이 존재합니다. 프롬프트의 자유도가 그만큼 높다는 것을 의미하죠. 어떤 프롬프트가 입력될지 알 수 없기 때문에 생성 모델이 아무리 많은 양의 데이터에 대해서 학습했다고 하더라도 개념에 상응하는 학습 이미지의 양은 많지 않습니다. 연구진은 특정 프롬프트에 대응하는 이 점에 착안하여 훨씬 적은 양으로 중독 공격을 성공적으로 진행했습니다.
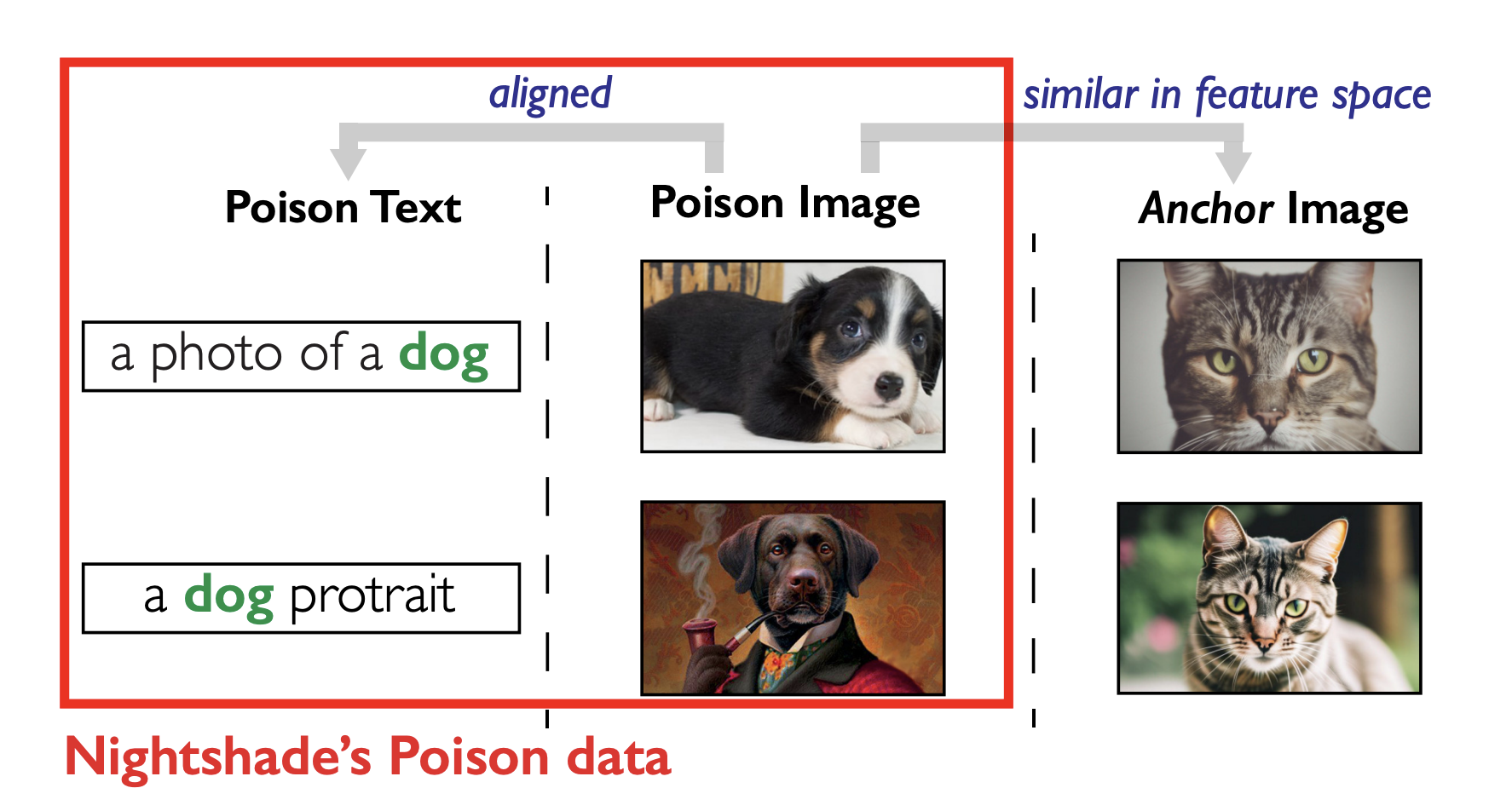
예를 들어, 개(dog)라는 단어가 데이터셋에서 얼마나 차지하고 있을까요? 연구진에 따르면 불과 데이터셋에 0.1%밖에 차지하지 않는다고 합니다. 그렇다면 개를 고양이로 바꾸도록 공격하기 위한 데이터의 양은 현저하게 줄어듭니다. 대중적인 키워드인 ‘개’에 대해서도 이러한데, 실제로 학습 데이터는 키워드별로 불균형이 심합니다. 다시 말하면, 다른 키워드들에 대해서는 공격하기 더 쉽다는 것이죠. 평균적으로 0.07%밖에 차지하지 않으며 60%의 데이터는 0.04%보다 적습니다. |