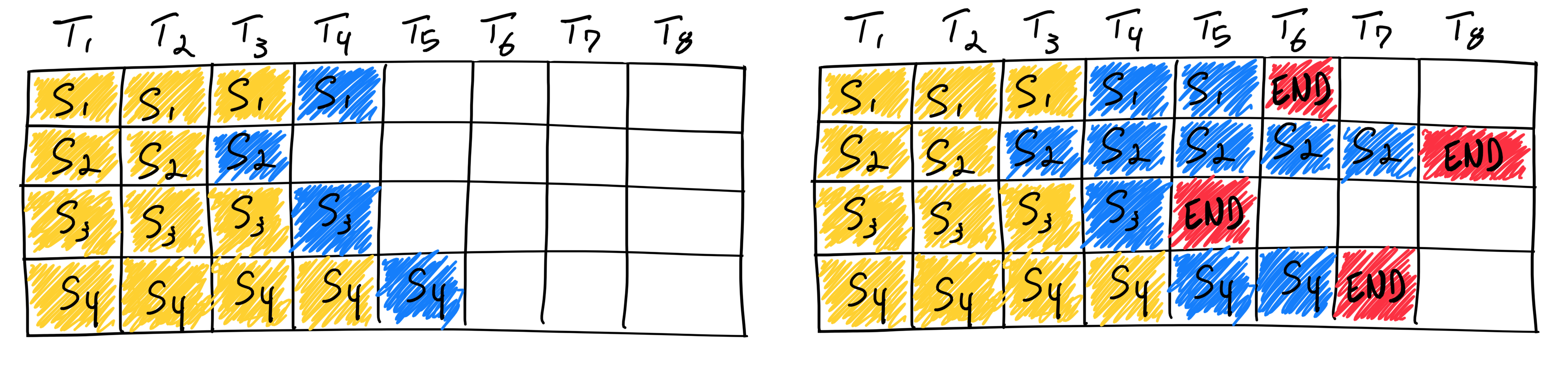
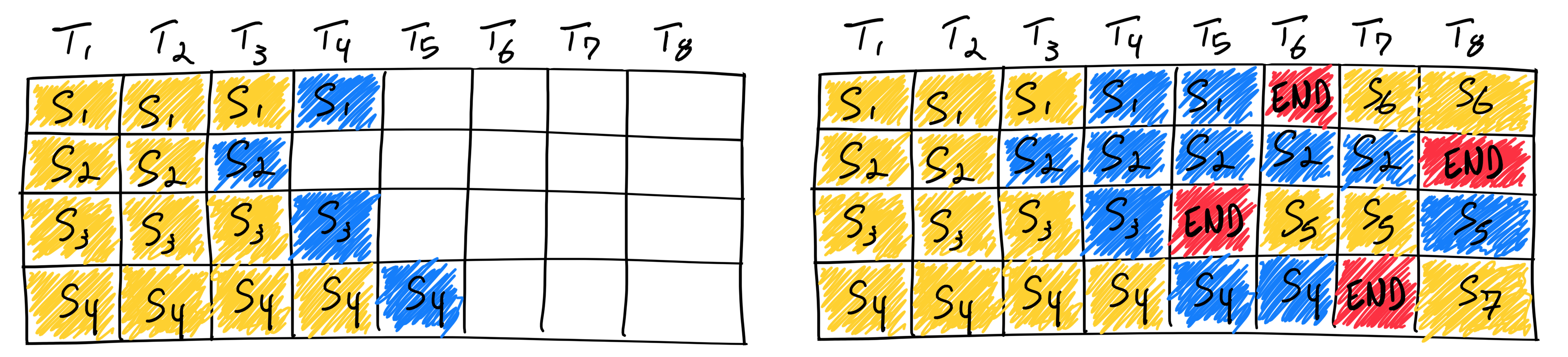
이는 Iteration-level Scheduling이라는 과정에 의해 이루어집니다. 스케줄러가 실행할 요청을 선택하면, 선택된 요청에 대해서는 단 한 번의 반복(Iteration)만 실행됩니다. 즉, 일단 하나의 토큰만을 생성하도록 지시하는 것이죠. 이후 실행 결과를 수신한 후, 완료된 요청이 감지되면 결과를 반환하고 새로운 요청으로 대체합니다.
그런데 Iteration-level Scheduling을 실제로 구현하기 위해서는 임의의 요청들을 배치 단위로 처리할 수 있어야 합니다. 문제는 각 요청마다 처리된 토큰의 개수가 다르기 때문에 모든 연산을 배치 처리할 수가 없다는 것입니다. 딥러닝 모델이 여러 데이터를 배치 단위로 처리하기 위해서는 각 데이터가 갖는 형태가 동일해야 합니다.
사실 배치 내 데이터의 형태가 같아야 한다는 제약은 Static Batching에서도 예외는 아닙니다. 하지만 Static Batching을 사용하는 상황에서는 길이가 짧은 시퀀스에는 패딩(Padding)이라는 기술을 적용해서 강제로 입력의 형태를 동일하게 맞춰줄 수 있었습니다. 또한, 짧은 응답이 생성된 시퀀스에는 긴 응답이 완료될 때까지 계속해서 패딩 토큰을 추가하면서 출력의 형태까지 일관되게 유지할 수 있습니다.
그런데 Continuous Batching에서는 패딩을 사용하여 데이터의 형태를 맞춰줄 수가 없습니다. 그래서 제안된 방법이 Selective Batching입니다. 이는 추론 과정에서 이루어지는 모든 연산을 배치 단위로 처리(Batchify)하는 대신, 선택된 일부 연산만 배치 단위로 처리하는 기법입니다. 예를 들어, 어텐션(Attention)과 관련된 연산은 요청별로 분리하여 처리하고, 선형 레이어(Linear Layer) 연산 등 다른 연산은 배치 처리를 수행합니다.
Continuous Batching은 최신 LLM 추론 과정에서 실제로도 널리 사용되고 있습니다. 특히 vLLM, HuggingFace의 Text Generation Interface(TGI)와 같은 주요 프레임워크에서도 적극적으로 도입되고 있습니다. 연구 결과에 따르면 GPT-3 175B 모델에서 기존 시스템 대비 무려 36.9배의 처리량(Throughput) 향상을 달성했다고 하며, 다른 연구에서도 Continuous Batching의 실질적인 효과가 입증되었습니다.
놀라운 점은 이 혁신적인 연구가 한국인 연구자들에 의해 최초로 제안되었다는 것입니다. Continuous Batching은 ORCA: A Distributed Serving System for Transformer-Based Generative Models 논문에서 최초로 제안되었으며, 이 논문은 2022년 USENIX OSDI라는 학회에서 서울대학교와 FriendliAI의 연구진이 공동으로 발표했습니다. 원래 Iteration-level Scheduling이라는 이름으로 제안된 이 기술은, 이후 Continuous Batching이라는 용어로 대중화 되었습니다. |