AI Trend/ News/ Meta/ DINOv2 2023 Sep Week 1 Datumo Newsletter |
|
|
Vision Foundation Model 'DINOv2' |
|
|
August 28th update on 'ChatGPT Enterprise'. Available from the day of release.
Image. OpenAI.
Meta announced on the 31st that they are providing a commercial license (apache 2.0) for their latest open-source model, 'DINOv2'.
According to Meta, DINOv2 is a foundation model based on the Vision Transformer, and it is highly suitable as a backbone for various computer vision tasks because of its excellent performance in image classification, segmentation, and search without the need for fine-tuning.
*The term 'backbone' model refers to the basic network structure that extracts features from data, and it serves as the foundational model for various tasks (e.g., VGG, ResNet).
|
|
|
SSL Model That Does NOT Require Labels |
|
|
Examples of Image Segmentation and Depth Estimation.
Source: 'DINOv2: Learning Robust Visual Features without Supervision'
Meta emphasized that 'Self-Supervised Learning (SSL)' has been utilized in DINOv2. Self-supervised learning is one of the methods where an artificial intelligence model learns from datasets without labels.
Self-supervised learning slightly differs from image-text pretraining (Vision-Language Pretraining), which has recently become the standard in training computer vision models. In the typical image-text pretraining process, the model learns by pairing images with their associated text, thus requiring labeled or annotated data.
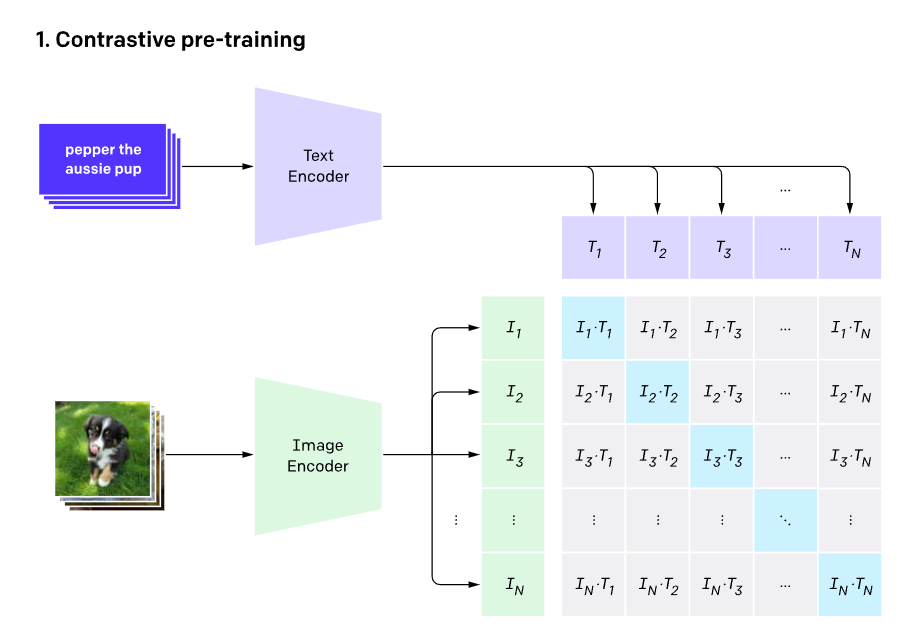
A prominent example of an image-text pretraining model is the 'CLIP' series released by OpenAI. CLIP utilizes images with captions for its pretraining. It transforms paired images and text into vectors of the same dimension (length) and trains in a direction where the similarity between the two vectors increases, enabling the artificial intelligence to associate and understand the image and its meaning.
|
|
|
CLIP: Overview of pretraining that connects text and images. Source: OpenAI.
However, according to Meta, this method has the risk of neglecting crucial information that is not explicitly stated in the captions accompanying the images.
For instance, if a picture of a chair in a spacious purple room has a caption stating "wooden chair," it is an inadequate description that doesn't capture the background and spatial information sufficiently. Thus, caption-based learning might result in reduced performance in downstream tasks that require more detailed information.
In contrast, when utilizing self-supervised learning, artificial intelligence can discern general features and patterns of data based on the intrinsic visual similarity of the images without relying on labeling information.
As a result, the bottleneck caused by data labeling during the model development process can be reduced. This allows for the utilization of more data for model training, and even datasets from specialized fields that are hard to label can be easily learned.
Currently, Meta revealed that they are working on specialized projects in various fields like medicine, nature, and environment using the DINO model.
|
|
|
Selection, Retrieval, & Augmentation Instead of Labeling |
|
|
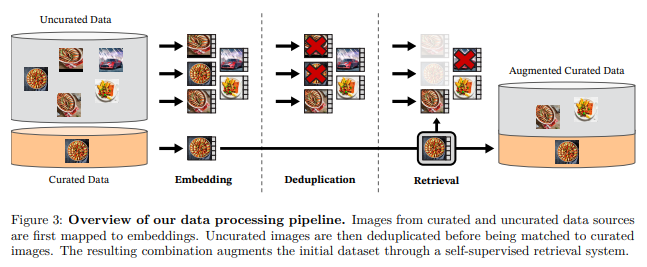
Overview of our data processing pipeline.
Source: 'DINOv2: Learning Robust Visual Features without Supervision'
Therefore, during the pre-training process of DINOv2, the primary focus was on data 'curation' rather than data labeling. Meta explained, "With no sufficiently large curated dataset available to suit our needs, we looked into leveraging a publicly available repository of crawled web data".
To build a large-scale pretraining dataset, two main steps are essential: removing irrelevant images and ensuring dataset balance. Manual curation is impractical, especially when dealing with non-metadata-associated distributions.
By selecting seed images from 25 third-party datasets and retrieving related images, we derived 142 million images from 1.2 billion source images.
|
|
|
This year, Meta has released many models as open source, including Llama, SAM, and DINOv2. As various individuals utilize these models, a developer community is forming, leading to faster technological innovation and increased societal impact.
Datumo is also actively utilizing semi-automatic labeling by integrating Meta's SAM (Segment Anything Model) into our data processing product. :) We're looking forward to the amazing and advanced technologies that Meta will unveil in the future!
References:
|
|
|
#Fine-tune your AI
From data planning, collection, processing, to screening and analysis, we will leverage your existing data as high-quality AI training data.
Implement a generative model optimized for your target function. |
|
|
The Data for Smarter AI
Datumo is an all-in-one data platform for your smarter AI.
|
|
|
Datumo Inc.
📋 contact@datumo.com
|
|
|
|
|