#모바일앱#별점분석#한화임팩트#DNA#그림#NFT
구독자님들, 안녕하세요! 스파이더킴의 데이터 뉴스레터 디귿입니다😊 이번 주차에는 웹크롤링으로 모바일 앱 별점 및 리뷰 분석하기, 한화임팩트의 DNA 기반 데이터 저장 기술 투자 소식과 AI 기술로 독창적인 예술작품 만드는 방법을 가져왔어요❗ 유익한 정보가 가득한 이번 주의 뉴스레터! 재밌게 읽어보시고, 행복으로 가득한 한 주가 되시길 바랄게요💕 '디귿'은 가장 쉬운 웹크롤링 서비스, 스파이더킴에서 발행하는 뉴스레터💌입니다. 스파이더킴에 방문하셔서 무료로 웹크롤링 서비스✨를 이용해보세요. 이번주에 디귿이 준비한 내용
1. [웹크롤링하는 한과장] 웹크롤링으로 모바일 앱 리뷰 및 별점 분석을
스마트폰 시대, 누구나 사용하고 있는 모바일 앱! 우리는 앱을 설치할 때 앱이 괜찮은지 파악하기 위해 별점을 보곤 하죠. 하지만 별점이 사용자의 만족도를 잘 반영하고 있는걸까요? 스파이더킴과 함께 구글 플레이스토어 앱 리뷰와 별점을 크롤링하고, 분석해보아요😊 "앱 사용자들의 만족도는 별점에 제대로 반영이 되고 있는걸까?"
플레이스토어에 있는 다양한 앱! 한과장은 웹크롤링을 통해 플레이스토어 내 무료앱 200개, 유료앱 195개에 해당하는 별점과 리뷰를 모아볼 거예요. 스파이더킴 홈페이지에 접속해 무료앱과 유료앱에 해당하는 URL을 넣어볼게요!
화면 옆에 웹 크롤링을 위한 툴바(Tool bar)를 활용하여 '상세 페이지' 정보를 추출해볼게요. 추출하고자 하는 정보는 별점과 리뷰 !! 원하는 항목을 클릭클릭~!👈
오늘도 몇번의 클릭으로 추출 완료✌ 추출된 파일들을 보며, 평점이 3.5 미만인 그룹1 과 3.5 이상인 그룹2로 나누어볼게요.
짠! 무료앱은 3.5미만의 별점을 준 68개의 리뷰와 3.5이상의 별점을 준 135건의 리뷰, 유료앱은 3.5미만의 별점을 준 36건의 리뷰와 159건의 리뷰가 준비되었네요⭐ 이제 각 그룹에서 많이 나오는 '명사' 단어들을 뽑아 그룹간의 차이가 얼마나 큰지 확인해볼게요. 우선, 무료앱 중 별점 3.5미만과 3.5이상 그룹 각각에 대해 단어를 뽑아 워드클라우드로 나타내보았어요😊  (별점 3.5미만)  (별점 3.5이상) 대략적으로 봤을 땐 비슷해보이지만, 자세히 보면 차이를 알 수 있어요. 별점 3.5 이상도 여전히 부정적인 표현이 많지만, 가장 극단적인 '최악', '취소' 등의 단어가 덜 보이네요. 하지만 여전히 '삭제', '문제' 등의 단어를 찾아볼 수 있었어요!
다음으로, 유료앱도 살펴볼게요!  (별점 3.5 미만)  (별점 3.5 이상) 유료앱의 별점 3.5 이상에서도 여전히 '환불', '문제' 등의 부정적인 단어를 찾아볼 수 있어요. 하지만 3.5 미만에서는 실질적 문제의 내용인 '버그', '오류' 등이 확연하게 보이네요!
부정적인 단어들의 정도의 차이가 있기는 하지만, 전반적으로 높은 별점에서도 부정적인 내용들이 많이 나타나는 것을 확인했어요. 실제로 아래와 같이 점수는 높지만 컴플레인에 가까운 내용들을 찾을 수 있었죠😥
최근 별점테러, 별점조작 등의 이슈로 별점을 폐지해야한다는 목소리가 커지고 있어요. 소비자에게 정확한 정보를 전달할 수 있고 서비스 제공자에게도 공정한 평가 시스템을 고민해볼 필요가 있겠네요🤔 웹크롤링 한과장 콘텐츠 잘 보셨나요? 한과장처럼 구글플레이스토어 크롤링을 해보고 싶다면? 아래 버튼을 클릭해 무료로 시작해보세요👇👇 2. 한화임팩트, DNA 기반 데이터 저장기술에 투자하다🧬
데이터, 어디에 저장하지?🤔 4차 산업혁명 시대의 핵심자원, 데이터! 데이터의 효과적인 활용 능력이 기업의 경쟁력을 좌우하는 시대가 왔어요. 하지만 매일, 모든 산업분야에서 대용량의 데이터가 쏟아지는 지금, 이대로는 데이터를 다 저장하지 못할 수도 있어요😥 데이터를 보관할 대용량 메모리의 중요성이 커지는 상황 속에서, 많은 기업들은 차세대 빅데이터 저장 기술에 주목하고 있는데요👀
(출처: 한화임팩트) 특히 한화임팩트는 지난달 30일, 미국 차세대 데이터 저장기술 회사인 카탈로그 테크놀로지스 (Catalog Technologies)에 투자했다고 밝혀 화제가 되고 있어요. 한화임팩트는 한화종합화학에서 회사명을 변경하고, 달라진 회사 정체성에 따라 미래 성장성이 높은 혁신기술의 발굴, 투자를 확대했는데요. 이번이 출범 이후 첫 투자이고, 3500만달러 (약 415억원)를 모집하는 시리즈(Series) B 자금 조달에서 최다 투자자로 참여했다고 해요! DNA에 데이터를 저장한다고? 한화임팩트가 거금을 투자한 카탈로그 테크롤로지스는 무려 DNA🧬를 기반으로 한 데이터 저장, 복원 기술을 개발하는 회사인데요😮 “DNA는 인체에서만 사용되는 용어 아니었어…?”👀 의아한 분들이 많으실 것 같아요. 하지만 생명체에 존재하는 DNA는 지구 상의 물질 중 가장 집약적으로 데이터 정보를 보유한 물질이랍니다!
DNA 메모리는 데이터를 4가지 염기서열 ‘아데닌(A)’, ‘구아닌(G)’, ‘시토신(C)’, ‘티민(T)’에 저장하고, A와 T의 결합은 0으로, C와 G의 결합은 1로 설정해 암호를 디지털화함으로써 저장 속도와 양을 폭발적으로 늘릴 수 있어요. 구체적으로는, 하드디스크의 1억배 이상을 보관할 수 있고 현재 전 세계의 모든 데이터를 1kg의 DNA에 다 담을 수 있을 정도라고 해요👍 심지어 저장기간도 반영구적이라고😮 한화임팩트가 투자한 카탈로그 테크놀로지스는 자체 개발한 기술로 DNA 기반 데이터 저장 비용과 속도를 개선해 DNA 메모리의 상용화를 앞당기는 데 기여했다는 평가를 받고 있어요. DNA 메모리가 상용화된다면 앞으로 미래 데이터 저장, 활용 전반에 있어 많은 혁신이 일어날 것으로 예상되는데요! 현재 전세계 데이터 저장량의 60%는 콜드 데이터 (Cold Data)예요. 콜드 데이터란 활발히 사용되는 핫 데이터 (Hot Data)와는 달리 접근 빈도가 낮은 데이터를 의미해요. 콜드데이터의 경우 저장비용을 감축하기 위해 주로 하드디스크드라이브(HDD)와 테이프에 저장되고 있지만, 저장밀도/보존기간/전력사용 등의 측면에서 한계가 지적되어왔죠. 하지만 저장밀도, 보존기간, 전력사용 측면에서 모두 우수한 DNA 데이터 저장 기술이 사용된다면, 기존에 버려지거나 활용되지 못한 콜드 데이터도 안전하게 보관하고 분석할 수 있고, 데이터의 활용을 극대화할 수 있어요😊 무궁무진한 데이터 세상🖥 이번 투자에 대해 한화임팩트는 "4차 산업혁명 시대에서 데이터는 기존 생산요소를 능가하는 핵심자원으로, 폭발적으로 증가할 것으로 전망된다"며 "데이터를 어떻게 저장하고 활용하느냐에 미래 경쟁력이 결정되는 만큼 차세대 데이터 저장기술에 주목하고 투자하게 됐다"고 밝혔어요. DNA 기반 데이터 저장 기술을 바탕으로, 무궁무진하게 데이터를 활용할 수 있는 세상이 곧 찾아올거예요😁 3. [데이터 분석] 그림 그릴 줄 모르는 사람도 창작으로 돈을 벌 수 있다면?
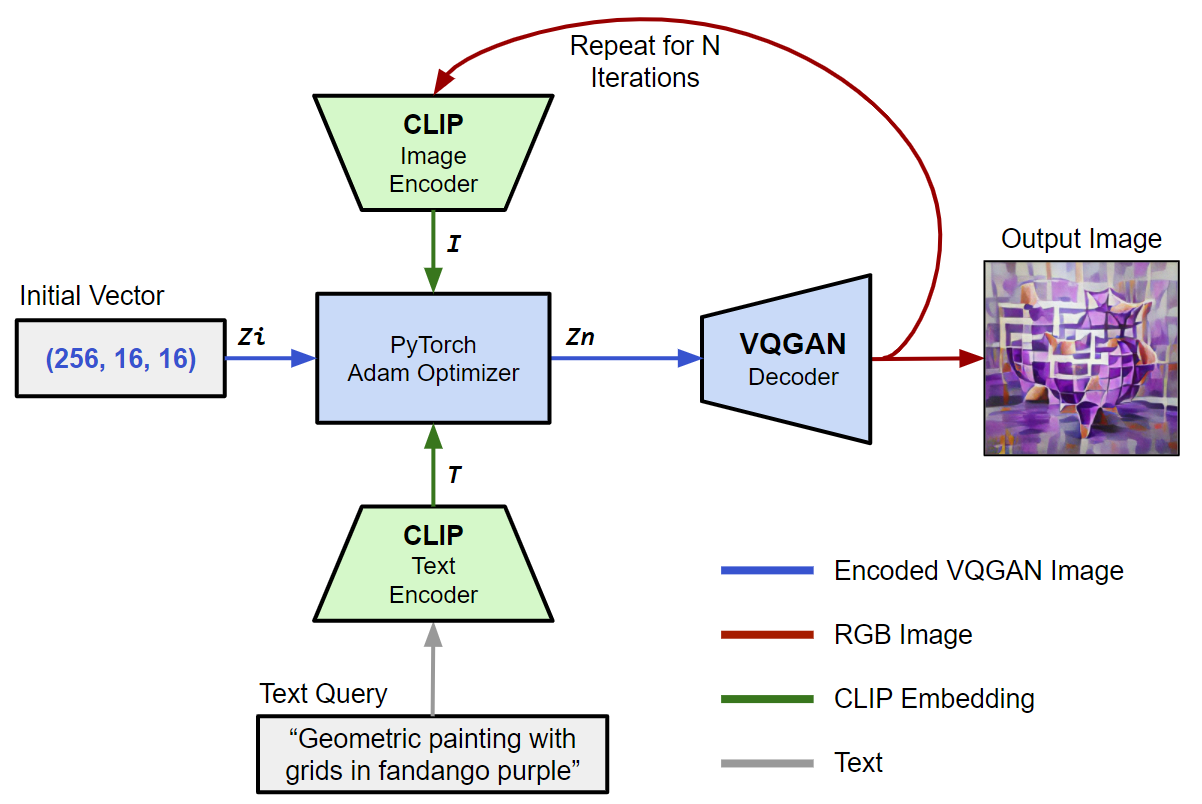
그림 그릴 줄 모르는 사람도 예술 작품을 팔아 이익을 남길 수 있는 방법이 있습니다. AI 기술을 활용해 예술작품을 창작하고 큐레이팅 할 수 있는데요. CLIP과 VQGAN Model을 활용해 높은 작품성을 지닌 디지털 페인팅 창작물을 만들어 내고 NFT로 판매하는 법, 오늘 알려드릴게요! "AI 기술로 하나뿐인 작품 만들어 세계적인 작가가 되보자고!✍" 학습부터 창작까지
위는 학습부터 창조까지의 과정을 보여주는 고도화된 시스템 구조도입니다. 위를 참조하여 각 단계의 세부 정보를 확인할 수 있습니다.🔍 우선 50,000개의 공공으로 사용 가능한 작품🎨을 WikiArt.org에서 가져와 VQGAN 모델을 학습시켰습니다. 또 OpenAI의 CLIP 모델을 이용해 작품을 인식/학습하는데 사용했습니다. 마지막으로 다시 VQGAN 모델을 활용하여 이미지를 만들어내는데요. 각 모델에 대해 자세히 알아볼까요? VQGAN 모델
VQGAN 모델은 ‘The Vector Quantized Generative Adversarial Network’의 약자로 벡터 양자화된 생산적 적대 신경망이라는 뜻입니다. 보통의 GAN 모델에서는 Generator와 Discriminator가 적대적으로 대립하면서 모델의 성능을 향상시키는데요. VQGAN 모델에서는 Encorder/ Transformer/ Decoder 단계에서 학습한 이미지를 세분화하여 가짜 이미지를 만들어냅니다. 그리고 Discriminator는 가짜 이미지와 진짜 이미지를 구별👥합니다. 이 모든 과정을 반복하면서 진품에 가까운 가짜 이미지를 만들어내고 또 그 가짜를 구별해내는 성능을 향상시킵니다.
위처럼 VQGAN 모델은 원래의 이미지를 잘 재현함에 더불어 눈과 입 등 몇몇 특징에서 구별되는 가짜 이미지를 만들어낼 수 있고, 이를 구별하는 능력
🎭 또한 가지게 됩니다. CLIP 모델 그럼 CLIP 모델에 대해 알아봅시다. CLIP은 ‘Contrastive Language-Inage Pre-training’의 약자로 자연어를 기반으로 정확한 이미지 분류를 수행할 수 있는 신경망입니다. CLIP 시스템에는 이미지 및 텍스트 인코더가 있는데 이를 Cross-modal 검색을 수행하는데 사용합니다.
아래 그림과 같이 이미지 데이터베이스가 있는 경우 이미지 인코더를 통해 각 이미지를 실행하여 이미지 임베딩 목록을 가져올 수 있습니다. 그런 다음 텍스트 인코더를 통해 ‘녹색 잔디밭에 앉은 강아지🐶’ 구문을 실행하면 해당 구문에 가장 적합한 이미지를 찾을 수 있습니다.
CLIP과 VQGAN 모델 활용하여 작품 만들기 CLIP 모델에 VQGAN을 이용해 만들어낸 가짜 이미지들을 학습시킵니다. 그리고 CLIP 모델에서 이미지/텍스트 인코딩, VQGAN 디코딩 과정을 거치면 내가 입력한 텍스트에 대응되는 독창적인 이미지🎨를 얻게 되는거죠.
결과 수백장의 이미지를 생성해보았을 때, 모든 작품이 예술적 가치가 있다고 보기는 어려웠는데요. 텍스트를 입력했을 때 원하는 구성을 갖춘 좋은 작품들도 있지만, 형태가 일그러져 가치가 없는 이미지들도 더러 있었습니다.
‘Bad’ 작품을 확인해보면, 각각 ‘호수’, ‘헤어드라이어’, ‘스컹크’라는 텍스트를 입력한 후 받은 결과값인데 형체를 알아보기 어려웠습니다.
만들어진 이미지를 NFT 시장에 판매할 수 있답니다! NFT가 뭔지 모르신다고요? 그럼 저번 블로그 게시글인 ‘NFT; 단 하나의 고유성을 지니다’ 를 확인해주세요!😀 💌피드백 보내주신 소중한 피드백을 바탕으로 디귿이 계속 발전하고 있어요🥰 정말 감사드려요! 디귿이 더 성장하기 위해, 의견이 있으시다면 적극적으로 말씀해주세요😊 그럼 오늘도 화이팅하세요✨ 오늘의 디귿은 여기까지! 이번주 디귿의 뉴스레터, 어땠나요? 좋았던 점, 아쉬웠던 점, 더 알고 싶은 점 마구마구 알려주세요! '디귿'은 가장 쉬운 웹크롤링 서비스, 스파이더킴에서 발행하는 뉴스레터💌입니다. 스파이더킴에 방문하셔서 무료로 웹크롤링 서비스✨를 이용해보세요. |