Synthetic Data / DALL-E 3 / Alpaca / AI Train data 2023 Oct Week 2 Datumo Newsletter |
|
|
📰 Synthetic Data in 'DALL-E 3' and 'Alpaca' |
|
|
Under the full moon, the bustling city streets are filled with pedestrians
enjoying the culture. DALLE 3. OpenAI.
Synthetic data refers to artificially generated data that mimics the statistical patterns of real datasets. It's utilized when it's difficult to obtain real-world data for training AI, especially in scenarios like medical or personal information which are restricted, or accident scenes where data instances are extremely scarce.
Recently, synthetic data is being widely used regardless of the type of model like vision or language. Considering the labeling cost, it's often more economical, and also competitive in terms of quality, ensuring a certain level of diversity in data.
In the recently released DALL-E 3 paper titled 'Improving Image Generation with Better Captions', the technology of synthetic data is emphasized. In this letter, we'll explore the use cases and side effects of synthetic data. 😃
|
|
|
Creating AI-generated descriptions for images to be trained |
|
|
Examples of images scraped from the internet and short synthetic captions (SSC), descriptive synthetic captions (DSC).
'DALL-E 3' is a state-of-the-art image generation model that creates remarkable images according to user prompts. To introduce how synthetic data was utilized in the training of 'DALL-E 3', let's briefly go over the training method.
During the pre-training stage, 'DALL-E 3' learns from a dataset where images and corresponding captions are paired together. Having pre-learned numerous images and their explanations, after the training, it can generate appropriate images in response to user prompts.
However, crucial information might be omitted in these 'captions'. According to researchers, details like text information within images or the color and size of objects are often missing. Hence, they decided to create appropriate captions separately for training.
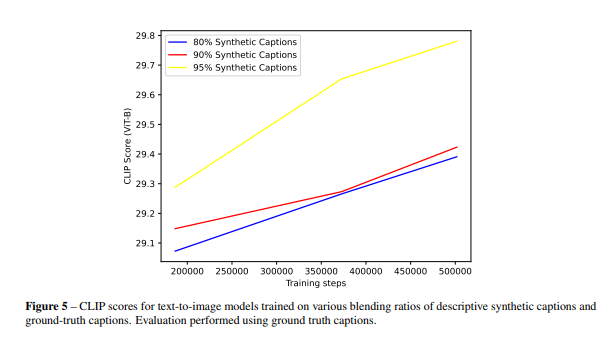
A bespoke image captioner is trained and used to rewrite the captions of the training dataset. Ultimately, 'DALL-E 3' was trained with a mix of 95% synthetic captions and 5% real captions, showing substantial improvement over its predecessor, DALL-E 2.
|
|
|
Comparison of model performance based on different caption types(CLIP Score).
as the ratio of synthetic captions increased, the performance improved.
|
|
|
"...We hypothesize that this issue stems from noisy and inaccurate image captions in the training dataset. We address this by training a bespoke image captioner and use it to recaption the training dataset. We then train several text-to-image models and find that training on these synthetic captions reliably improves prompt following ability." Improving Image Generation with Better Captions, James Betker et al. OpenAI
|
|
|
Case of 'Alpaca' and side effects of synthetic data |
|
|
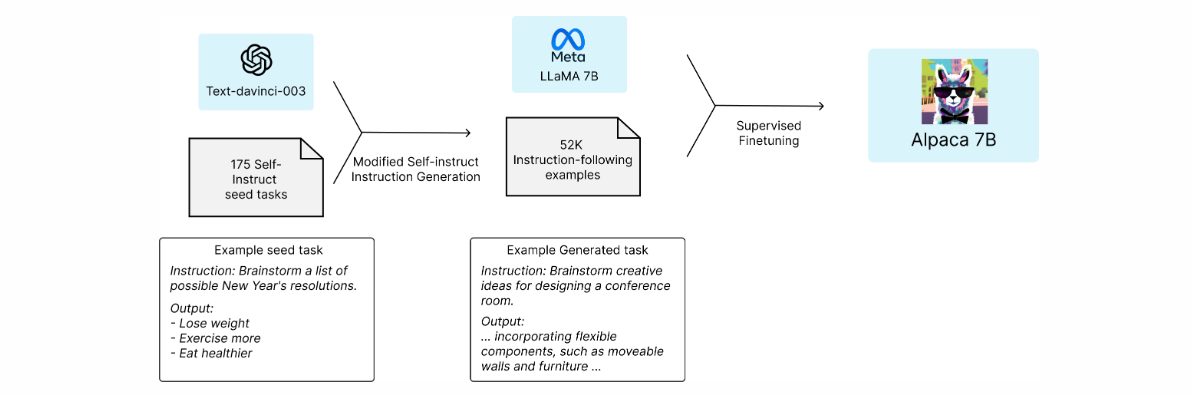
Overview of Alpaca model training. Link.
In the domain of large language models(LLM) too, synthetic data is actively utilized. A notable example is the case of Alpaca, where Stanford University fine-tuned the open-source model 'Llama 2' in March, using 52,000 examples created by GPT 3.5(text-davinci-003). Despite having a relatively fewer parameter count of 7 billion, Alpaca showed similar performance to GPT 3.5, and the research team disclosed that the cost for data generation via GPT API was under $500.
|
|
|
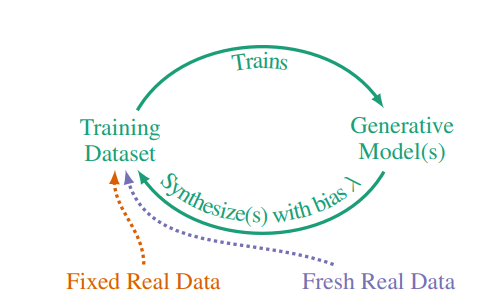
Self-consuming loop when utilizing generated model outputs for training.
Source: Self-Consuming Generative Models Go MAD
In July, researchers from Rice University and Stanford University published a paper with the intriguing title, 'Self-Consuming Generative Models Go MAD'
The key content is as follows:
“Generative models are being trained on synthetic data from generative models,” “This creates a continuous self-consuming loop, and at each loop stage, without enough fresh real data, the accuracy of future generative models decreases. We call this state Model Autophagy Disorder (MAD), drawing an analogy to mad cow disease.”
Thus, the overtraining of artificial intelligence on synthetic data is likened to mad cow disease and is also referred to as ‘Habsburg AI’. At Datumo, when utilizing synthetic data, we meticulously go through algorithm-based data similarity analysis and full inspections by human labelers! We wanted to mention this as we conclude the letter 🙂
|
|
|
The Data for Smarter AI
Datumo is an all-in-one data platform for your smarter AI.
|
|
|
Datumo Inc.
📋 contact@datumo.com
|
|
|
|
|